

目次
中国のAI企業「DeepSeek」が、わずか数百万ドルという比較的低いコストで、OpenAIのGPT-4に匹敵する性能を実現したというニュースは、多くのビジネスパーソンにとって非常に衝撃的な話題でした。LLMモデルの高性能、低コスト化というトレンドは、企業が生成AIにどのように取り組むべきかを考えるうえで、重要な示唆を与えてくれます。以下では、DeepSeekのAI業界にもたらす影響、そして大企業が2025年に生成AIを活用するヒントを解説します。
中国のAI企業「DeepSeek」が安価に高性能LLMを開発したニュースが世間を賑わせましたが、DeepSeekの影響はどの程度あるのでしょうか。また大企業が2025年に生成AIを活用するにはどうしたら良いのでしょうか。
DeepSeekの主な技術的イノベーション
DeepSeekが注目を集めた背景には、4つの革新的な技術的要素があります。
1つ目は「Mixture of Experts(MoE)」で、大規模なモデルを複数の〝専門家〟に分割し、必要に応じて最適な専門家だけを起動する仕組みです。これにより、すべてのパラメータを一斉に動かさなくても高精度が維持でき、計算コストを大幅に削減できます。
2つ目の「Multi-Head Latent Attention(MLA)」は、会話の文脈などを保持するメモリ領域を効率よく管理し、一般的なLLMモデルと比べて膨大なメモリ使用量を大幅に抑えている点が特徴です。
3つ目は、強化学習の一手法である「GRPO(Group Relative Policy Optimization)」で、出力の品質を相対評価しながら学習を重ねることで、高度な推論力を持つLLMモデルをシンプルな設計で実現しています。
最後に「Distillation(知識蒸留)」が加わり、大型モデルの知識を小型モデルへ効果的に継承させることで、エッジ環境などでも高い性能を発揮できる仕組みを完成させました。
これら4つの要素が組み合わさることで、DeepSeekは従来の〝巨大化一辺倒〟とは異なる、高効率かつ高性能なLLMモデルを実現しているのです。
DeepSeekの「5.5百万ドルでGPT-4に匹敵」は誇張
メディアでしばしば目にする「DeepSeekは550万ドル程度でGPT-4相当を作り上げた」という話は、実態を一面しか捉えていません。確かに本番トレーニングにおけるGPU稼働費用だけを見れば、この数字に収まると公表されています。しかし、研究開発に着手する前の試行錯誤や追加のインフラ投資を含めると、総額は少なくとも10億ドル規模に達しているといわれています。
つまり、550万ドルというのはあくまで「本番学習」の一部コストであり、DeepSeekが高性能なLLMモデルを生み出すために投じたリソース全体を示しているわけではありません。それでも、米国の大手AI企業がさらに巨額の投資を続けている状況と比べると、DeepSeekの取り組みはより効率的であることは確かで、ここに大きな注目が集まっています。
DeepSeekの登場でGPU需要は減るのか
LLMモデルの計算コスト削減が進むと、GPUなどの需要が減るかのように思われがちですが、実際にはAIをより安価に動かせるようになると、多くの企業や機関が導入を検討し始め、結果としてトータルのGPU需要は拡大すると考えられます。
DeepSeekの効率化技術が注目を集めた際も、NVIDIAの株価は一時的に動揺があったものの、その後は需要見込みが上向きだという評価が再浮上しました。さらにDeepSeekのような小型で高性能なLLMモデルが公開されれば、オンプレやエッジで運用したい企業も増え、新たな市場が生まれます。こうした動きは、AI導入の裾野を広げる一方で、計算インフラ全般の需要を押し上げるでしょう。
2025年に大企業が生成AIを活用するためのヒント
かつては「膨大なデータを持ち、大規模に学習できるLLMプレイヤー」がAIを独占するという見方が主流でした。しかしDeepSeekのようにより少ないリソースでも十分な性能が出せるなら、単なる〝巨大LLMモデル競争〟だけでは差別化が難しくなっています。
大切なのは、いかに特定の業界や業務に垂直特化して学習を回し、素早く精度向上を図るか。また、オンプレやエッジを含めてどのようにデプロイメントを設計し、最適化するか。こうした要素が、今後の差別化の核心になります。大企業にとっては、豊富な自社データと現場知識を組み合わせ、独自の学習ループを回す戦略が鍵を握ります。大企業が2025年に生成AIを活用するためのヒントを4つのポイントで整理します。
①大規模LLMモデルを〝そのまま〟使うだけでは差別化できない
2025年のAI業界では、膨大な資金を投じて巨大なLLMモデルを利用するだけでは、もはや持続的な競争優位を築きにくいと考えられています。最新のLLMモデルは、博士号レベルの科学知識において人間を凌駕するレベルまで到達しています。
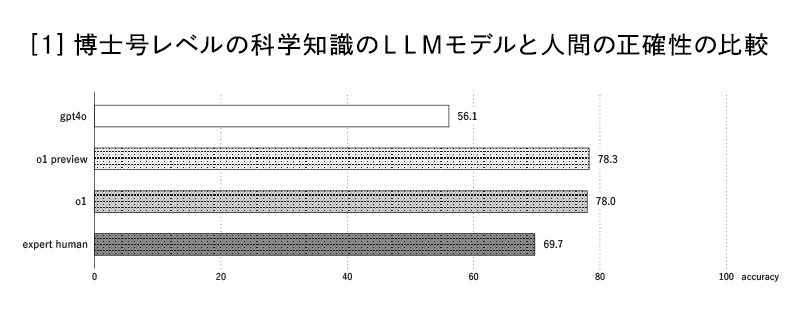
むしろ注目されているのは、「どのように自社の固有知識や運用設計と組み合わせ、LLMモデルを〝賢く〟活用するか」という点です。たとえば、オンプレミス環境で細かくチューニングしたり、社内データを使って部分的に再学習を回したりすることで、大企業ならではの豊富なリソースを効率的に活かすことができるでしょう。
それに加えて、LLMモデルを一から自社開発するか、外部のLLMモデルをベースにするかも柔軟に選択できる時代になっています。過度に自前主義にこだわらず、最適な部品を〝アセンブル〟する形でAIを取り込むことが、大企業には求められているのです。
② AIを〝組織・ビジネスモデル〟ごと変革する覚悟が必要
生成AIが進化したことで、ソフトウェアが「人の業務を支援する」段階から、「AI自体が仕事を代行し、人間は監督や調整を担う」形へとシフトしつつあります。これにより、企業内の組織構造やビジネスプロセスを根本から見直さなければならないケースが増えています。
たとえば、経理や人事のバックオフィス業務をAIエージェントに大きく任せる場合、人間の担当者が不要になる業務領域が出てくるため、余剰人材を別の価値創造部門へ配置転換する必要が生じるでしょう。
こうした変化に対応するには、現場の混乱を最小限に抑えつつ、経営陣がスピード感を持って意思決定を下す体制が重要です。AIを導入すれば即座に劇的な効果が得られるわけではなく、組織変革や人材再配置に取り組む「覚悟」が必要といえます。
③〝マルチエージェント〟や〝複数LLMモデルの連携〟が新たなイノベーション源に
これまでのLLMモデル開発は、1つの巨大LLMモデルがあらゆる機能を担う形が主流でした。しかし、2025年には複数のエージェントやLLMモデルを組み合わせる動きが目立ってきています。たとえば、データ収集や分析が得意なエージェントと、意思決定や実行部分を担うエージェントを分業させるほうが、総合的なパフォーマンスや柔軟性が高まるのです。
大企業の場合、部署によって扱うデータの種類や目的が異なるため、それぞれの業務領域に特化したLLMモデルを連携させるほうが理想的といえます。これには、社内システムやクラウドサービスとの高度な連携設計、セキュリティや権限管理の慎重な運用が不可欠です。とはいえ、その分だけ現場での運用体験は飛躍的に向上し、新しい付加価値やイノベーションを生み出す余地が生まれます。単一の巨大LLMモデルだけでは不可能だった応用範囲を広げられるため、競合他社との差別化にもつながるでしょう。
④コスト削減 vs 売上向上
大企業において、生成AIを導入する際は、単なるコスト削減のみに注目してはいけません。
AIの導入コストが下がったとしても、精度や信頼性が不十分なモデルを選べば、後々の品質トラブルやブランドリスクで余計な出費を招きかねません。一方で、売上向上へ直結する領域、例えば新製品開発や顧客対応の高度化などにAIを投資すれば、その効果は長期的な収益増につながります。
したがって、まずはリスクとリターンの評価を的確に行い、必要最低限のコスト圧縮を図りながら、付加価値を創出する分野へ優先的にリソースを配分することが重要です。
まとめ
2025年のAI活用は、これまでの延長線上にある「大規模LLMモデルを導入して終わり」というアプローチとは大きく異なります。むしろ、大企業が直面するのは「現行のビジネスモデルや組織構造、インフラ設計をどうアップデートするか」という本質的な課題です。単なるコスト削減を目的とするのではなく、品質と信頼性を最優先し、組織変革とセットで進めることで、生成AIの持つ潜在的な価値を最大限に引き出すことができます。
また、マルチエージェントによる分業も、今後は企業の成長に欠かせない要素となるでしょう。ビジネスパーソンとしては、AIを自社の強みと組み合わせ、社内外のエコシステムをどう形成するかを見極めることが、勝ち残りの鍵となりそうです。
Profile
シバタ ナオキ 氏
元・楽天株式会社執行役員、東京大学工学系研究科助教、スタンフォード大学客員研究員。東京大学工学系研究科博士課程修了(工学博士、技術経営学専攻)。スタートアップを経営する傍ら「決算が読めるようになるノート」を連載中。